



A few months ago, we launched an online service that allows anyone to publish their data visualizations from Python or R, and then easily arrange them into interactive dashboards through a drag-&-drop interface. The idea was to give data scientists a tool to share their insights with others in a form similar to dashboards using pure Python or R and not requiring additional programming or front-end development.
Such a code can be invoked from either Jupyter notebook, RMarkdown, Python, or R scripts. Once the data is pushed, it can be accessed via a browser.
import matplotlib.pyplot as plt
from dstack import create_frame
def line_plot(a):
xs = range(0, 21)
ys = [a * x for x in xs]
fig = plt.figure()
plt.axis([0, 20, 0, 20])
plt.plot(xs, ys)
return fig
frame = create_frame("line_plot")
coeff = [0.5, 1.0, 1.5, 2.0]
for c in coeff:
frame.commit(line_plot(c),
f"Line plot with the coefficient of {c}", {"Coefficient": c})
frame.push()
Published visualizations could be combined into “dashboards” and shared with other people. Other people in this case would not see the code but would be able to see the visualizations and interact with them.
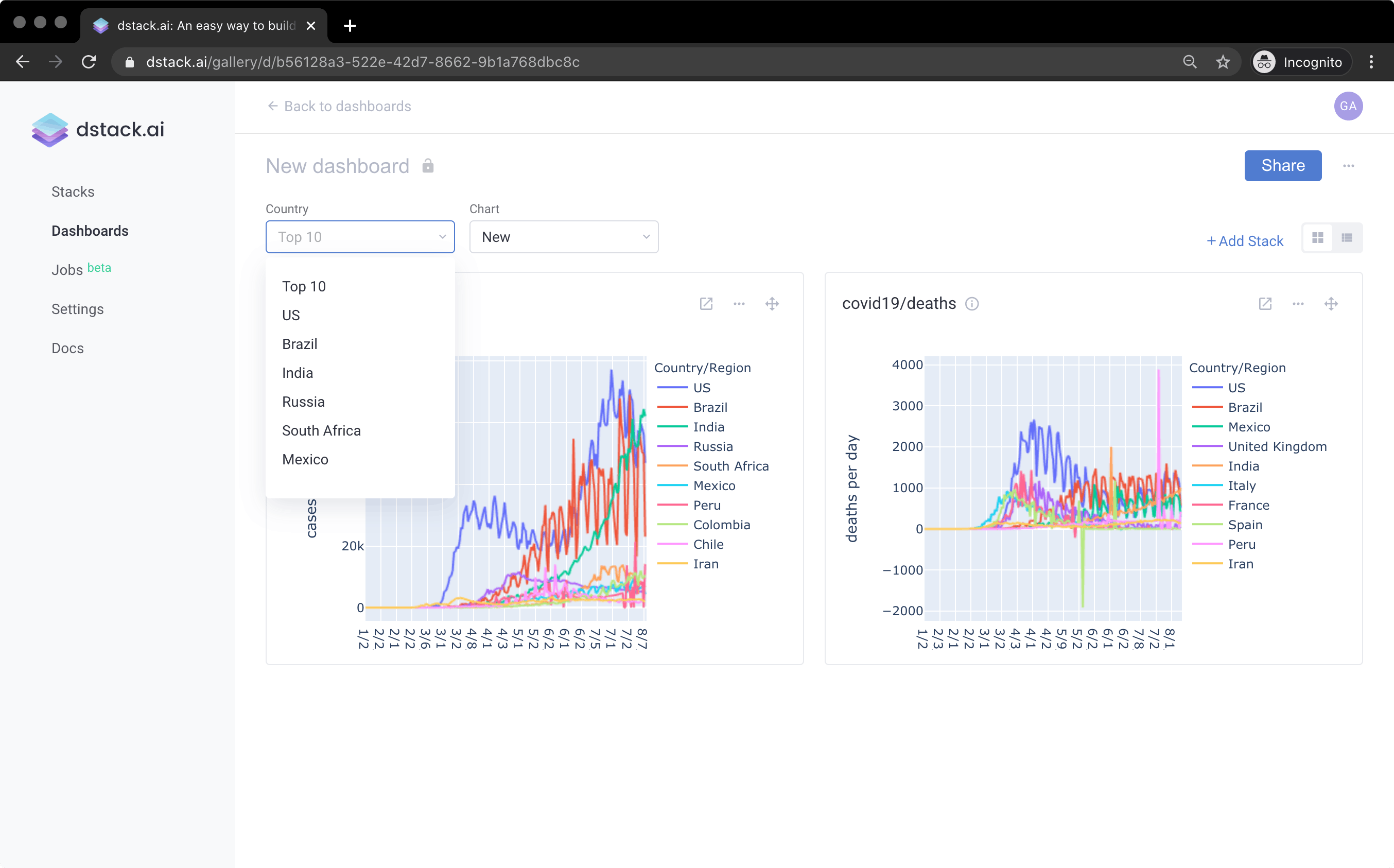
What we learned
When we showed dstack.ai to some of our friends from the data science community, we received quite positive feedback. Most of the positive feedback came from the two categories of people: People that wanted to quickly create and share interactive dashboards or reports using pure pandas and plotly, or tidyverse and ggplot2 People that used Plotly Dash or R Shinyapps but didn’t like that it required them to do programming and maintenance for the applications
While users didn’t mind putting their data to dstack.ai for public reports and dashboards, for any private data, most users told us that they would rather not put their data (and their customers’ data) into a proprietary cloud such as ours and that they are quite concerned about the privacy of the data. This was tough feedback for us as we designed dstack.ai as a cloud service in the first place.
Open-sourcing dstack
After putting some thoughts into this, we realized that making dstack.ai open-source and making it free to use by anyone can bring us more value long-term than offering it as an in-cloud service only.
When we started building the presentation layer, we quickly realized that dstack.ai should integrate a lot more open source data science frameworks than we integrated ourselves. For example, as a user, I can push a matplotlib plot, a Tensorflow model, a plotly chart, a pandas dataframe, and I expect the presentation layer to fully-support it. Supporting all types of artifacts and providing all the tools to work with them solely seems to be a very challenging if not impossible task.
If we want the presentation layer to support many different use-cases, we would have not only to build a lot of these integrations but also give users tools to build those integrations themselves to extend dstack.ai with custom functionality.
Privacy is of course also important. If such a tool is to be used by the data science community and enterprises, it must respect and protect the privacy of the data.
All the above made us decide to open-source all core features of dstack.ai. Now you can build dstack locally, and run it on your servers, or in a cloud of your choice if that’s needed.
More details on the project, how to use it, and the source code of the server can be found at the github.com/dstackai/dstack repo. The client packages for Python and R are available at the github.com/dstackai/dstack-py and github.com/dstackai/dstack-r correspondingly.
The server side is written in Kotlin and is licensed under Apache 2.0. The Python client is written in Python and is licensed under Apache 2.0. The R client is written in R and is licensed under GPL 3.
Open-source vs Enterprise
How does open-sourcing change our plans to monetize the platform through dstack.ai? Or do we still want to monetize dstack.ai? Given that the project is still in its infancy, one of our primary responsibilities is going to be maintaining the open-source project and growing the community of the users, rather than monetization. We plan to improve the open-source tool by making it more robust and extensible. Our secondary responsibility will of course remain to develop and maintain the in-cloud service and also learn how the tool can be even more useful for enterprises.
What’s next
Now that we’ve open-sourced dstack, we plan to extensively extend the list of use cases for this tool.
User callbacks
Currently, dstack allows the user to pre-calculate matplotlib/ggplot2/plotly/bokeh visualizations, associate them with particular parameters, and combine into a single dashboard. This way the user may build relatively simple dashboards that work with static data. A downside of this is that one has to pre-calculate visualizations in advance so the dashboard cannot work with dynamic data. Even though dstack.ai lets the user schedule jobs to update dashboards (this is, for example, how our “COVID Cases and Deaths” dashboard works), this is still not convenient and might not work in a lot of scenarios (mainly because often it’s very difficult if not impossible to pre-calculate all the combinations).
This is why we’d like to extend dstack with the support for user callbacks, so the application not just shows one of the pre-calculated visualizations, but can fetch data from a store, process it in realtime and generate visualizations when a user changes an input parameter.
ML models
Another important feature, we’re going to start working now is ML models. Today, more and more data tasks are solved with the help of ML models. ML models become more efficient and now can be applied to a growing variety of use cases. This includes NLP, computer vision, AutoML, and other promising ML directions. With dstack, we’d like to make it possible for data scientists to build applications that solve important business problems with ML in minutes and not days or weeks. We plan to achieve that by using the same approach dstack uses for visualizations: the user uses a notebook or a job to publish a Stack which binds together a pre-calculated ML model and user parameters.
Use cases
How is this going to be different from Shiny, Dash, and Streamlit? Today making data applications requires a lot of things. First, the core feature of data applications is working with data. Thus, making data applications requires data science skills. Second, because data applications are in a way still applications, they need to be developed, deployed, and maintained, and scaled as any traditional applications. Thus, it requires development and deployment skills too. We believe data scientists should focus on data science and not application development. At the same time, we believe it’s super important to turn data science models into applications as fast as possible as it reduces the time-to-insight.
While a lot of companies have no problems extending their core products with ML (simply because these teams have all the needed stuff), a lot of other departments in companies would also greatly benefit from applying data science and ML but these teams do not have resources to implement, deploy, and maintain these applications on their own. This is where we believe dstack is going to find its niche. Mainly because dstack won’t require its users (data scientists) to do any programming, deploying, or maintenance.
And finally, we believe the value dstack will bring is exactly a way to build data and ML applications for internal use inside companies (HR, Sales, Logistics, Marketing, Management, Finance, Legal, Customer Service, Operations, etc).
Having said that, there's too much already on the plans! Let's get back to the present.
What to do now?
- Download dstack locally and try how it works
- Read the documentation to learn how to use it
- Sign up for the in-cloud version and see if you can use it
- Build your first dstack application
- Suggest us a feature, report a bug, or just tell us about your use case
- Share it with your colleagues which you think can benefit our of it
- Contribute
Your dstack.ai team